SignSynth
Pose2Video model driven by point-like conditions for posture data, based GAN.
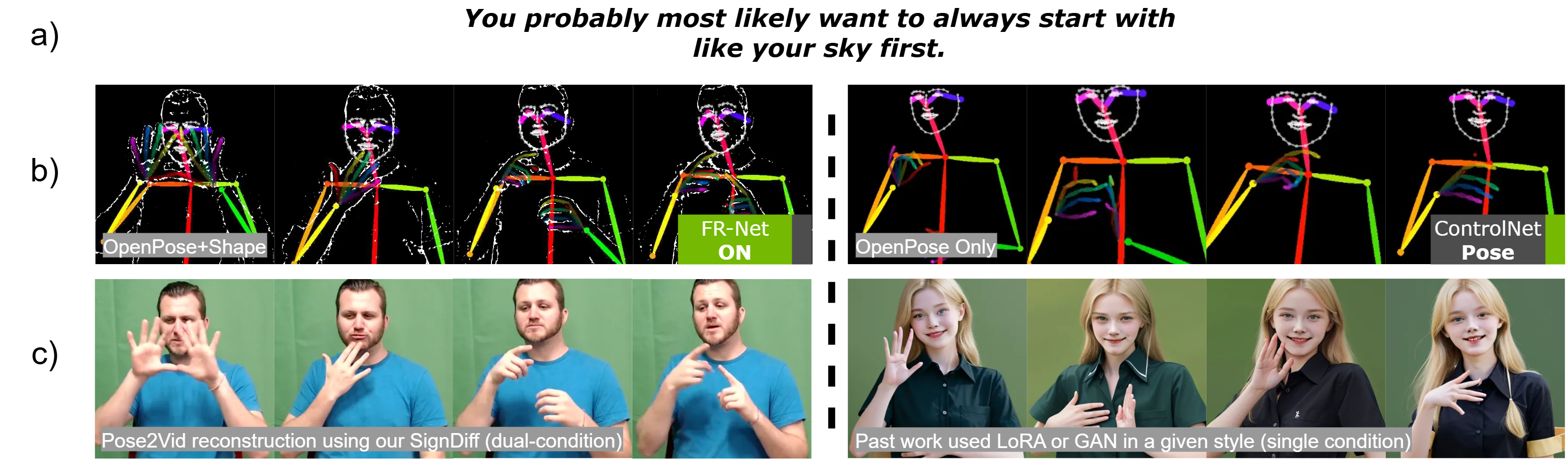
In this paper, we propose a dual-condition diffusion pre-training model named SignDiff that can generate human sign language speakers from a skeleton pose. SignDiff has a novel Frame Reinforcement Network called FR-Net, similar to dense human pose estimation work, which enhances the correspondence between text lexical symbols and sign language dense pose frames, reduces the occurrence of multiple fingers in the diffusion model.
In addition, we propose a new method for American Sign Language Production (ASLP), which can generate ASL skeletal pose videos from text input, integrating two new improved modules and a new loss function to improve the accuracy and quality of sign language skeletal posture and enhance the ability of the model to train on large-scale data.
We propose the first baseline for ASL production and report the scores of 17.19 and 12.85 on BLEU-4 on the How2Sign dev/test sets. We evaluated our model on the previous mainstream dataset PHOENIX14T, and the experiments achieved the SOTA results. In addition, our image quality far exceeds all previous results by 10 percentage points in terms of SSIM.
Final Videos vs. Ground Truth.
Simple demonstration of workflow.
Pose2Video model driven by point-like conditions for posture data, based GAN.
Image generation for skeletal posture control, which is based on pix2pixHD implementation.
@misc{fang2025signdiffdiffusionmodelamerican,
title={SignDiff: Diffusion Model for American Sign Language Production},
author={Sen Fang and Chunyu Sui and Yanghao Zhou and Xuedong Zhang and Hongbin Zhong and Yapeng Tian and Chen Chen},
year={2025},
eprint={2308.16082},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2308.16082},
}
@misc{fang2024signllm,
title={SignLLM: Sign Languages Production Large Language Models},
author={Sen Fang and Lei Wang and Ce Zheng and Yapeng Tian and Chen Chen},
year={2024},
eprint={2405.10718},
archivePrefix={arXiv},
primaryClass={cs.CV}
}